【新智元导读】LLM的数学推理能力缺陷得到了很多研究的关注,但最近浙大、中科院等机构的学者们提出,先进模型在视觉推理方面同样不足。为此他们提出了一种多模态的视觉推理基准,并设计了一种新颖的数据合成方法。
无论是语言模型还是视觉模型,似乎都很难完成更抽象层次上的理解和推理任务。
语言模型已经可以写诗写小说了,但是依旧算不对9.11和9.9比大小的问题。
同样的问题也出现在视觉模型中,它们能完美理解自然景色或人物照片,却无法处理各种图表任务,甚至看表读时间都是难题。
如果要将AI系统用在更多专业领域,这些能力缺陷就显得极为突出。
最近,浙江大学、中科院软件研究所、上海科技大学等机构就联合提出了一种新的多模态基准,专门衡量模型对抽象图像的理解能力和视觉推理能力。

论文地址:https://arxiv.org/pdf/2407.07053
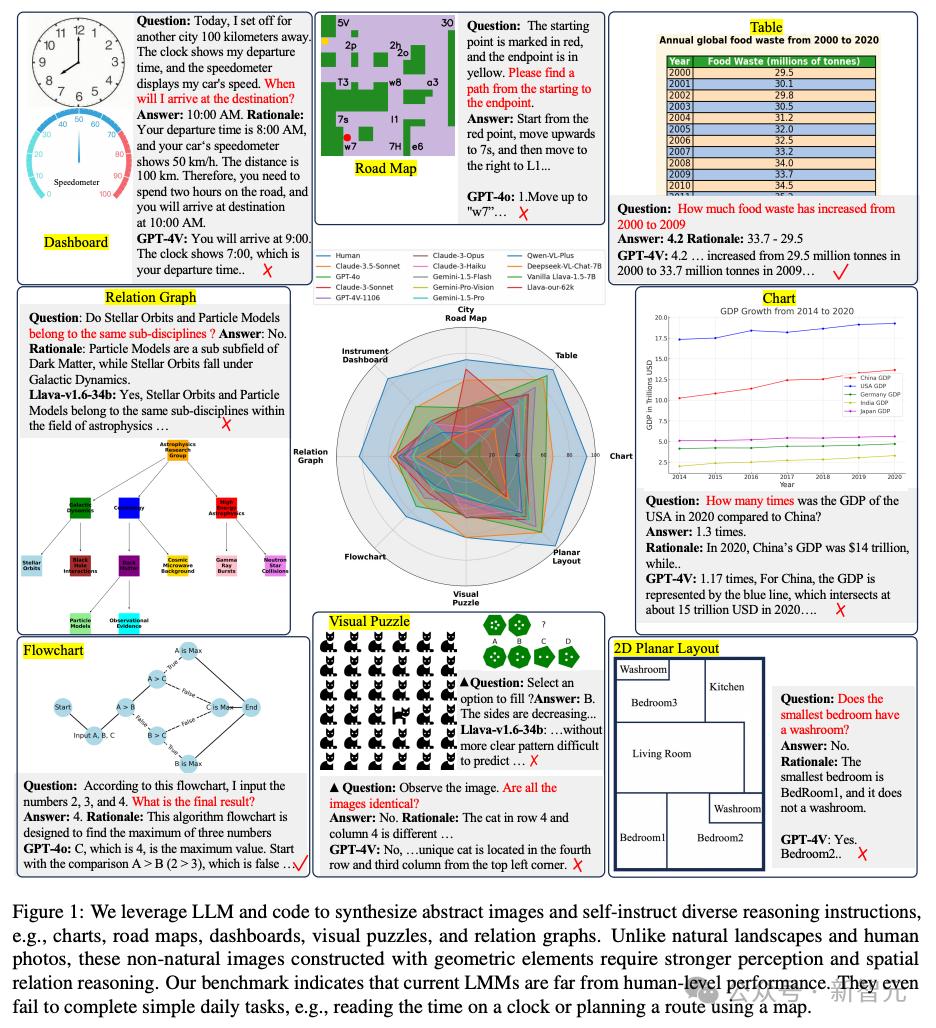
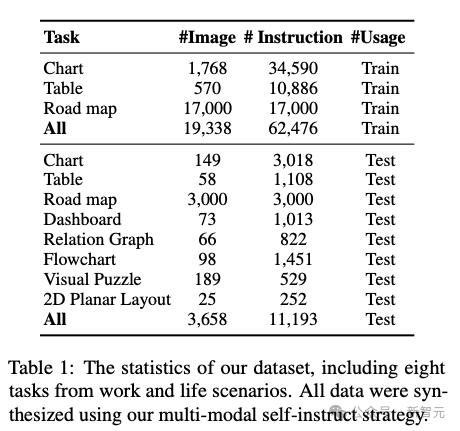
数据集共包含11,193个带有相关问题的抽象图像,涵盖了仪表板、路线图、图表、表格、流程图、关系图、视觉谜题和2D平面图等8大类别,此外还有额外的62,476条数据用于微调模型。
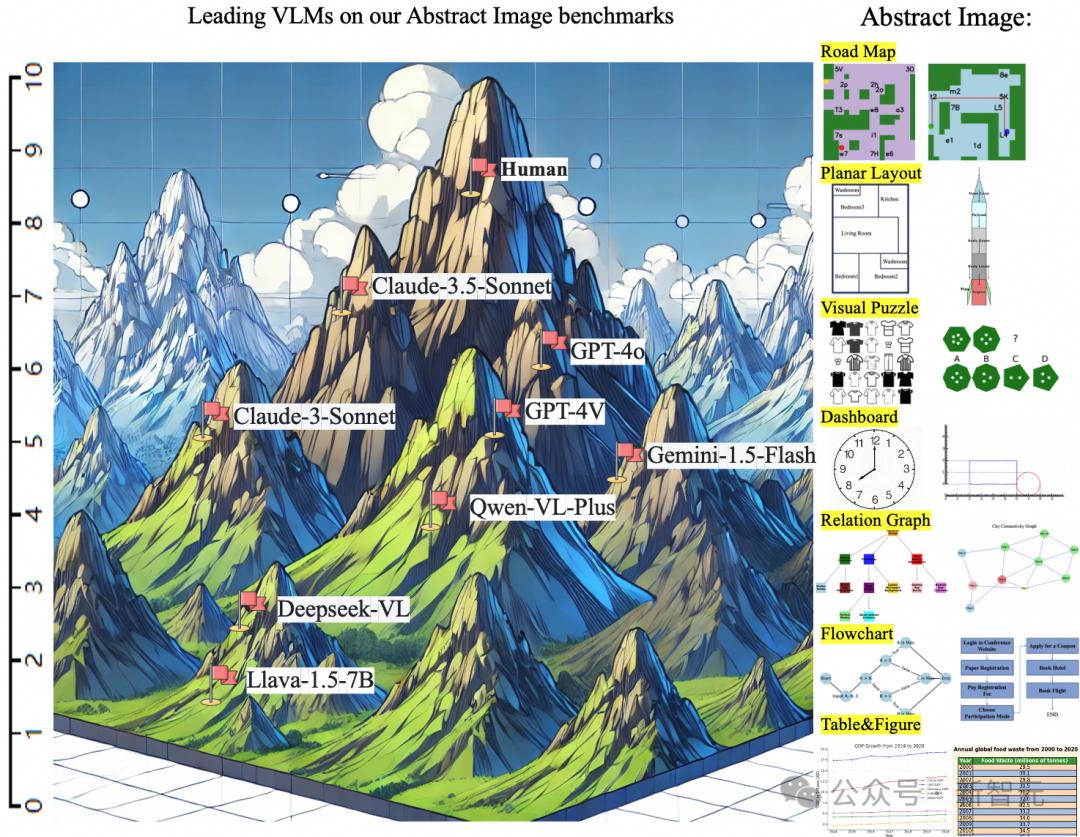
经过测试,人类在该基准上可以达到至少82.1%的准确率,但Claude 3.5 Sonnet和GPT-4o等顶流模型的成绩却远远落后于人类,分别只有64.7%和59.9%。
目前全部数据已经上传至HuggingFace仓库。

仓库地址:https://huggingface.co/datasets/zwq2018/Multi-modal-Self-instruct
此外,作者也将数据构建数据所用的代码上传到了GitHub。
代码地址:https://github.com/zwq2018/Multi-modal-Self-instruct
构建数据集
作为新提出的基准测试,重头戏自然是数据集的构建过程。
作者在论文中指出,想要采集到合适的抽象图像-文本对,既需要大量人力,也十分耗费时间。
那么使用合成数据呢?
同样也不容易,因为我们需要的是多模态数据,但LLM无法直接生成图像,DALL-E、Stable Diffusion等图像生成模型又无法同步生成文本。
一个直觉的解决方案是将二者结合在一起,直接生成<图像,问题,答案>形式的数据。
但文生图模型实际上很难对图像细节做到细微精准的控制,尤其是生成仅由几何形状组成的抽象图像,更何况其中大部分还需要包含数字和文字。
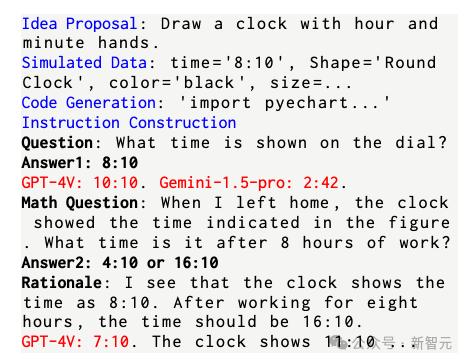
鉴于以上问题,作者提出了一种以代码为中心的「自我指导」(self-instruct)策略进行图像和相关文本的同步合成,整个过程只有语言模型——GPT-4-Turbo的参与,没有用到图像生成模型。(图2)

首先指导LLM,针对某个日常情景,提出一种视觉创意。这个过程中,作者给LLM提供了一些in-context示例,使生成结果尽可能涵盖全部8个类别。
然后模型根据自己提出的创意,生成所需的数据和代码以绘制图像。
比如对于饼状图,LLM就需要先「捏造」数据,设计出每个类型对应的百分比数值。在代码生成中,作者激励模型使用Matplotlib或ECharts等代码库,显著降低了代码复杂度。
执行代码并渲染好图像后,LLM会继续进行「自我指导」,根据视觉内容,加上之前所用的视觉创意、数据和代码作为prompt,生成多个高质量的<问题,答案>文本对。
除了为每个问题生成答案,作者还提示LLM生成能解释答案的「原理」(rationale),以便用于训练模型,起到类似于CoT的作用。
整个构建过程的流水线如下图所示:
这种「以代码为中心」的方式不仅更容易保证图像的细节、质量和多样性,也让LLM更容易生成相关文本。
数据合成过程所用的模型是GPT-4-Turbo,但合成后还经过Llava-1.5的初筛,以保证图像的美观程度、布局合理性以及文本可读性等。
最终构建的测试集共包含3.658张图像和11,193条指令,涵盖了仪表板、路线图、图表、表格、流程图、关系图、视觉谜题和2D平面图等8个类别。
数据集进行了10%的随机抽样,并让人类验证答案的正确性,发现数据集的质量有一定的保证。
为了能进一步评估合成数据的质量,作者还为图表、表格和路线图这三个任务构建了额外的训练集,共包含62,476条指令(图1)。
基准测试
论文共对12个模型进行了测试,详细结果如表A1所示,其中人类所得分数来自于两个本科生分数的平均。
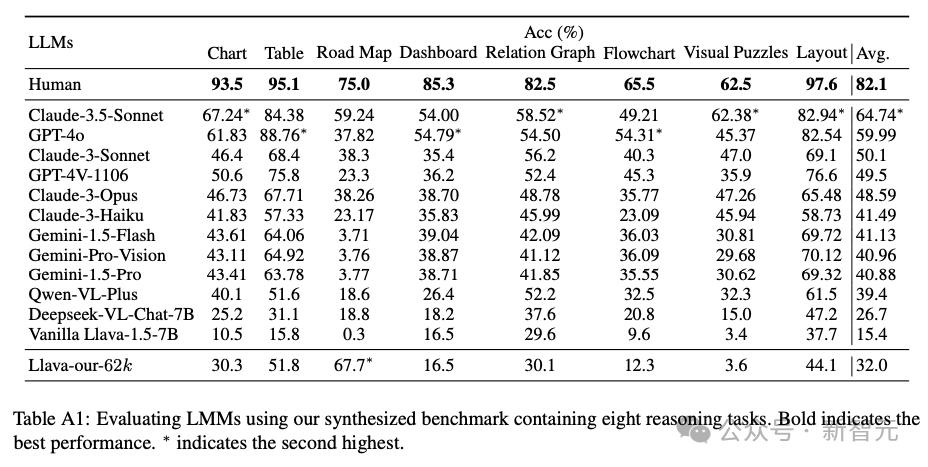
其中得分最高的是Claude 3.5 Sonnet,平均准确率为64.74%;GPT-4o紧随其后,准确率为59.99%,都与人类平均水平82.1%相去甚远。
作者发现,在图表、关系图、2D平面图中,模型经常在抽象概念或空间关系上出错。
8个类别的抽象图像中,模型表现最差的当属「路线图」类。Claude 3.5 Sonnet平均准确率为59.24%,其余模型均为未超过40%。
在「路线图」和「视觉谜题」两类图像任务中,开源和闭源模型的差距尤为明显。
模型微调
除了构建基准,论文发现,用这些合成数据训练模型可以显著提高其视觉推理能力。
相比之前的Vanilla Llava-1.5-7B,用62K条数据经过4小时LoRA微调后的模型,在3类图像任务上都有非常显著的提升。尤其是「路线图」类别,准确率飙升67.4%,超过了GPT-4V和Claude-3-Sonnet(表2)。
虽然模型在微调后出现性能提升属于正常现象,但这种微调效率可以侧面证明合成数据的潜力,尤其是在质量、有效性和多样性方面。
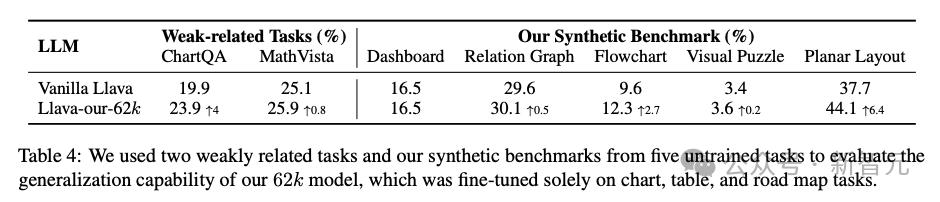
除了在原基准上有所进步,微调后的模型在ChatQA、MathVista这样弱相关任务上也有不同程度的分数提升(表4)。
这意味着,在合成数据上的训练可以提升模型的通用视觉推理能力,从而泛化到其他任务,而非仅仅是拟合训练场景。
结论与限制
论文最重要的贡献在于指出了当前多模态LLM在视觉推理方面的次优表现,并构建了合成数据组成的基准测试集,表明合成数据训练是一个有前景的解决方案。
与此同时,作者指出了该研究存在的三方面限制:
- 数据合成过程严重依赖LLM的代码合成和推理能力,因此论文只使用了GPT-4等闭源模型。随着Llama 3等开源模型逐渐提升性能,未来可以利用开源模型合成数据以减少成本
- 本项工作主要用代码合成8类的抽象图像,例如表格和地图,未来可以继续扩展到用代码控制机器人仿真器,生成特定的房屋布局和结构
- 我们认为视觉编码器是当前LLM的瓶颈,尤其是对于抽象图表而言,因此未来提升编码器图像分辨率可以增强LLM的细粒度认知能力
参考资料:
https://the-decoder.com/study-reveals-major-weaknesses-in-ais-ability-to-understand-diagrams-and-abstract-visuals/
https://arxiv.org/abs/2407.07053



